
What is a Bulelng inspection? It is an Inspection to ensure the safety of the person and their
belongings while in the United States or Canada. It is commonly known as a “Building Survey”,
because it is usually conducted by …
Security Guard Employment

Security guard employment is especially dangerous, statistics show. Security guards are three
times more likely to sustain injuries than the average employee. Across the world, the general
incidence rate for fatalities on security guard jobs varies significantly and is notoriously …
The effects of human activities on natural landscapes

Landscape design has been viewed traditionally as in Germany and other German-speaking
countries. According to this traditional concept, adelaide pergolas landscape already has the following functions: (1
Protection of persons, animals and property; (2) Production (of biomass, water, vegetation,
etc. …
What Conveyancing Entails
Conveyancing Melbourne should be considered when buying or selling.
Conveyancing, in simple terms, is the legal process of transferring ownership of an asset from
one person or corporation to another. This is an important aspect to consider when buying or…
How Do Painters Move Furniture?

How can you prevent your painter’s ruining your home? How can you stop your painter from ruining your home? How can you avoid your Painters Brisbane ruining your home and property? How can you stop your painter destroying your home? …
What is the Purpose of Underpinning?

Cracked walls or floors could be an indicator that your property requires underpinning to help stabilize and protect from further damage. By undertaking this process, it will help stabilize your home and prevent further deterioration.
Underpinning is a process which …
Why Businesses Need Professional Embroidery Machines

Professional embroidery machines help businesses produce their embroidered products more efficiently and with greater control of quality and branding.
Finding the appropriate commercial embroidery machine doesn’t need to be challenging. By choosing a company with exceptional support, training, and warranty …
The Meaning of matial arts

Martial Arts have many meanings. These can range from self-defense and police/military instruction to self-expression and weapons based combat. Discover the meanings behind martial arts. This article will cover the most commonly used ones, including: Self-defense Many people believe that…
The Agency – A Brief Overview of Real Estate Services
The Agency was founded in Beverly Hills by Billy Rose and Mauricio Ummansky in 2011. The real estate firm has become a popular name in the Los Angeles area thanks to its stellar agent performance. The agency’s first year, its …
How to book a massage at a body massage spa
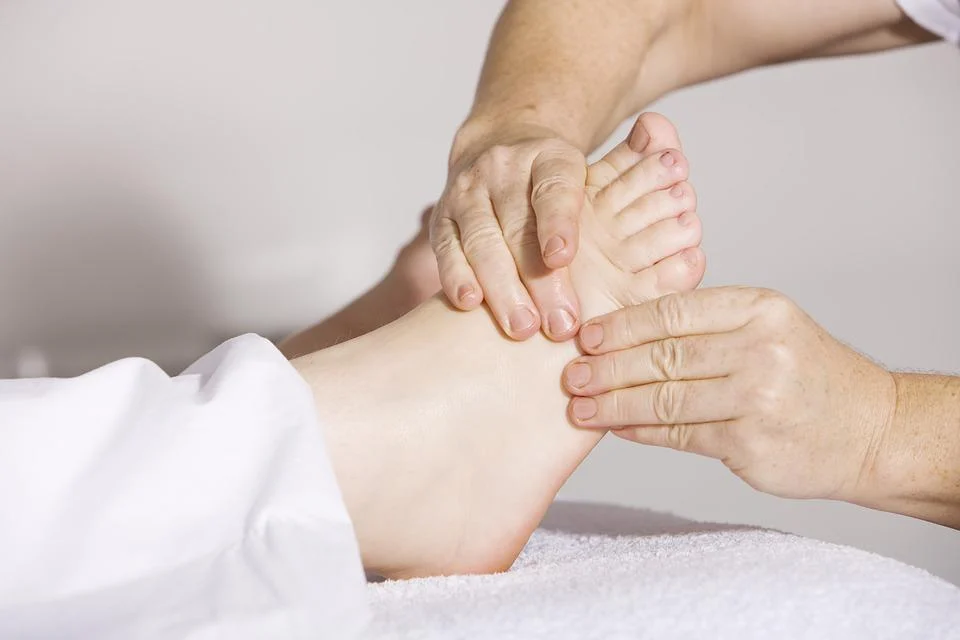
The first step is to book a massage at a spa. The pressure will be adjusted by a skilled therapist to meet your needs. Good therapists will ask you first if the pressure is comfortable. If they are not comfortable…